Unintended Variable Shadowing
Uintended Variable Shadowing中文翻译过来是:非预期变量遮蔽
在讲解什么是非预期变量遮蔽前需要知道什么是变量遮蔽。
变量遮蔽: 当内层作用域中定义了一个与外层变量同名的变量,此时在内层作用域中遮蔽了外层变量,此时该外层变量会被暂时的遮蔽了。
非预期变量遮蔽: 由于编写代码的过程中疏忽了导致了外层变量被遮蔽,从而导致程序产生了bug。简而言之就是开发者想要操作外层变量,但是是实际上操作的是内层作用域的变量。
下面展示一个由于不变量的非预期遮蔽从而产生的副作用:
func TestUnintendedVariableShadowing(t *testing.T) {
var client *http.Client
tracing := false
if tracing {
client, err := createClientWithTracing() //重现定义了client变量,该变量只存在if作用域,与外层作用域的client是两个独立的变量
if err != nil {
fmt.Println(err)
}
log.Println(client)
} else {
client, err := createDefaultClient()
if err != nil {
fmt.Println(err)
}
log.Println(client)
}
useClient(client)
}
func createClientWithTracing() (*http.Client, error) {
return &http.Client{}, nil
}
func createDefaultClient() (*http.Client, error) {
return &http.Client{}, nil
}
func useClient(client *http.Client) {
if client == nil{
fmt.Println("nil client")
}else{
fmt.Println("正确传入client")
}
}
首先根据上述代码,我们可以发现,在if语句块中client使用了短变量声明运算符,此时的client是全新的变量,我们本来想着是生成tracing client 或者默认client 然后使用该client,但是最后我们发现,useClient传入的参数是nil。
如何修改上述代码,让其外层变量不被遮蔽:
- 在
if语句块中创建临时变量,然后再语句块尾部将该临时变量赋值给外层的client。
func TestUnintendedVariableShadowing(t *testing.T) {
var client *http.Client
tracing := false
if tracing {
c, err := createClientWithTracing() //重现定义了client变量,该变量只存在if作用域,与外层作用域的client是两个独立的变量
if err != nil {
fmt.Println(err)
}
log.Println(c)
client = c
} else {
c, err := createDefaultClient()
if err != nil {
fmt.Println(err)
}
log.Println(c)
client = c
}
useClient(client)
}
func createClientWithTracing() (*http.Client, error) {
return &http.Client{}, nil
}
func createDefaultClient() (*http.Client, error) {
return &http.Client{}, nil
}
func useClient(client *http.Client) {
if client == nil {
fmt.Println("nil client")
} else {
fmt.Println(client)
}
}
还有一种解决方案就是类似于上述情况,内部作用域变量是通过函数创建的,那么可以先声明一个error类型的变量,然后使用=操作符而不是:=短变量声明操作符。
func TestUnintendedVariableShadowing(t *testing.T) {
var client *http.Client
tracing := false
var err error
if tracing {
client, err = createClientWithTracing() //重现定义了client变量,该变量只存在if作用域,与外层作用域的client是两个独立的变量
if err != nil {
fmt.Println(err)
}
log.Println(client)
} else {
client, err = createDefaultClient()
if err != nil {
fmt.Println(err)
}
log.Println(client)
}
useClient(client)
}
如果使用了第二种方案,可以将没有必要在每一个条件分支进行处理error,因为条件分支判断err逻辑是一样的,这样可以在两个条件分支外层判断该err。
func TestUnintendedVariableShadowing(t *testing.T) {
var client *http.Client
tracing := false
var err error
if tracing {
client, err = createClientWithTracing() //重现定义了client变量,该变量只存在if作用域,与外层作用域的client是两个独立的变量
log.Println(client)
} else {
client, err = createDefaultClient()
log.Println(client)
}
if err != nil {
fmt.Println(err)
}
useClient(client)
}
如何避免非预期变量遮蔽
- 遵循清晰的命名规范,避免同名冲突,
拒绝使用count,data,num等通用的变量名,给变量起【具有描述性】的名字,比如:globalIrderCount,localNewOrderCount,从根源减少不同作用域的同名概率。
- 利用开发工具和静态检查工具,在开发阶段即使发现遮蔽问题。
- 避免不必要的变量声明。
Go语言内置类型
对于类型来说,需要清楚两个问题:
- 需要分配多少内存?
- 这些内存用于存储什么类型?
1. 整数
对于整型类型来说:
int 和 uint:
-
int8:- 内存: 1个字节(8 bit)
- 存储类型: 有符号整数
- 范围: -128 - 127
-
int16- 内存: 2个字节(16- bit)
- 存储类型: 有符号整数
- 范围: -32768 - 32767
-
int32- 内存: 4个字节(32- bit)
- 存储类型: 有符号整数
- 范围: -2147483648 - 2147483647
-
int64- 内存: 8字节个字节(64 bit)
- 存储类型: 有符号整数
- 范围: -9223372036854775808 - 9223372036854775807
-
uint8- 内存: 1个字节(8 bit)
- 存储类型: 无符号整数
- 范围:0 - 255
-
uint16- 内存: 2个字节(16 bit)
- 存储类型: 无符号整数
- 范围: 0-65535
-
uint32- 内存: 4个字节(32 bit)
- 存储类型: 无符号整数
- 范围: 0-4294967295
-
uint64- 内存: 8个字节(64 bit)
- 存储类型: 无符号整数
- 范围:0-18446744073709551615
如果我们使用非精确类型
int或者uint来声明变量时,该变量的存储大小实际上取决于用于构建程序的硬件架构。
32位架构: int用4字节存储有符号整数,uint用4字节存储无符号整数
64位架构: int用8字节存储有符号整数,uint用8字节存储无符号整数。
2. float
Go语言遵循IEEE 754二进制浮点算数标准,仅支持两种类型浮点数:
float32- IEEE 754标准:单精度浮点数
- 字节数:4字节
- 指数位长度: 8bit
- 位数为长度: 23位
- 有效十进制精度(约): 6-7位
float64- IEEE 754标准:双精度浮点数
- 字节数:8字节
- 指数位长度: 11bit
- 尾位数为长度: 52位
- 有效十进制精度(约): 15-16位
未精确指定float的时候默认是float64。
浮点数存在固有舍入误差,无法精确表示部分十进制小数,比较时需使用容差判断,避免直接使用 ==。
3. bool
// true and false are the two untyped boolean values.
const (
true = 0 == 0 // Untyped bool.
false = 0 != 0 // Untyped bool.
)
bool类型只有两个值,true或者false, 在Go语言中不能将整型变量直接转换成bool类型,也不能将bool类型转换成整型。
4. string
// string is the set of all strings of 8-bit bytes, conventionally but not
// necessarily representing UTF-8-encoded text. A string may be empty, but
// not nil. Values of string type are immutable.
type string string
字符串类型在go1.20版本中没有在builtin.go中具体实现,但是在builtin.go文件中类型定义了string,在builtin.go文件中递归类型定义了string,递归类型定义只能适用于内置基本类型,普通自定义类型无法复刻。
type int int
//如果类型定义类型本身,则会有错误提示
//invalid recursive type: int refers to itself
在builtin.go文件中我们可以知道 字符串是所有8位字节的字符串的集合,通常但不一定表示UTF-8编码的文本。字符串可以是空的,但不是nil。字符串类型的值是不可变的。
Unnecessary nested code
Unnecessary nested code中文: 不必要的嵌套代码
首先我们分析一个丑陋的例子:
// 很丑陋的版本
func join(s1, s2 string, max int) (string, error) {
if s1 == "" {
return "", errors.New("s1 is empty")
} else {
if s2 == "" {
return "", errors.New("s2 is empty")
} else {
concat, err := concatenate(s1, s2)
if err != nil {
return "", err
} else {
if len(concat) > max {
return concat[:max], nil
} else {
return concat, nil
}
}
}
}
}
func concatenate(s1, s2 string) (string, error) {
return s1 + s2, nil
}
这个例子虽然逻辑上是正确的,但是它涵盖了太多层次的if-else,导致代码阅读起来相对困难,你个良好的代码,是在大致阅读代码的时候就知道这段代码是什么意思,而不是需要一步一步的看。
对于上述代码的优化版本:
// 自行先优化一下
func joinV2(s1, s2 string, max int) (string, error) {
if s1 == "" || s2 == "" {
return "", errors.New("s1 or s2 is empty")
}
concat, err := concatenate(s1, s2)
if err != nil {
return "", err
}
if len(concat) > max {
return concat[:max], nil
}
return concat, nil
}
// 100 mistakes 书本中在不涉及改动部分功能下优化版本
func joinV3(s1, s2 string, max int) (string, error) {
if s1 == "" {
return "", errors.New("s1 is empty")
}
if s2 == "" {
return "", errors.New("s2 is empty")
}
concat, err := concatenate(s1, s2)
if err != nil {
return "", err
}
if len(concat) > max {
return concat[:max], nil
}
return concat, nil
}
一般来说函数所需的嵌套层次越多,就与但阅读和理解。
接下来我们来看一下,如何避免太多层次的if-else。
-
当一个if语句块返回时,我们应该在所有情况下省略else语句块。
-
当然也可以走一个相反的路径,比如说
if condition {return }那么我们也可以将condition修改为`if !condition{//执行业务逻辑}else {return}。 -
尽可能将正常执行的代码,对齐到代码的左侧。
我们分析一下糟糕版本的代码,发现正常执行的代码一直在右侧挪动,如果这个嵌套层次更深,那么正常执行的代码还要继续往右侧移动。所以说我们尽可能将正常执行的逻辑对齐到代码的左侧,这样在阅读代码的过程中,很轻易的知道这段代码到底是要做什么。
字长
字长是指,在某种特定架构下,存储整数及指针所需要分配的内存容量。
32位架构: 字长位4字节,因此需要分配4字节的内存空间。
64位架构: 字长位8字节,因此需要分配8字节的内存空间。
也就意味这指针类型变量,分配4字节或者8字节,根据不同的架构分配不同的大小的内存空间。
所以在相同的架构环境下,对于int、指针或者字的数据来说,为他们分配的内存容量始终相同的。
misusing-init-functions
滥用初始化函数
Go语言中的init函数
在Go语言中,init函数是一个内置的特殊函数,其主要特征如下:
- 函数签名固定:
func init(){}无参数、无返回值 - 无法被程序显式调用
- 由
Go语言运行时系统在程序启动阶段自动执行。
init 执行规则
init函数的执行是在包级全局变量初始化之后,main函数执行之前
// utils.go
package utils
import "fmt"
var Count int
func init() {
Count = 1
fmt.Println("我是init函数,我是否在main函数执行之前")
}
func AddCount() {
Count++
}
func GetCount() int {
return Count
}
// main.go
package main
import (
"100-mistakes/code-and-project/utils"
"fmt"
)
func main() {
fmt.Println(utils.GetCount())
utils.AddCount()
fmt.Println(utils.GetCount())
}
// output:
// 我是init函数,我是否在main函数执行之前
// 1
// 2
从上面的程序运行结果可以看出,init是在main函数之前就执行了。
多个init函数执行的顺序:
- 同一个源文件下,
init的执行顺序为定义顺序
// init.go
package utils
import "fmt"
func init() {
fmt.Println(1)
}
func init() {
fmt.Println(2)
}
func init() {
fmt.Println(3)
}
func init() {
fmt.Println(4)
}
func init() {
fmt.Println(5)
}
func init() {
fmt.Println(6)
}
// 首先不用再main中单独引入该源文件,由于上面的程序中已经引入该包,而init函数的执行过程中是在包导入的时候就执行了
// output:
// 1
// 2
// 3
// 4
// 5
// 6
- 同一个包内多个源文件: 按照源文件名称的字字母顺序执行。
就按照上述utils包中有两个源文件add.go和init.go,这两个源文件中都定义了一个或者多个init函数,按照字母顺序add.go中的init函数是优先执行,然后再是init.go中的init函数。
- 不同包之间,按照导入依赖的顺序,被导入的包先执行
init然后是当前包的init。
init函数的常见使用场景
- 初始化全局变量
首先我们知道init函数的执行是在包全局变量初始化之后,在main函数之前,那么我们可以在使用全局变量之前将复杂赋值的逻辑放在init函数中,这样在导入包的过程中,全局变量就已经初始化完成了。
- 注册驱动/插件
Go生态中很多场景依赖init函数注册驱动,比如数据库驱动.
-
加载配置/初始化资源
比如程序启动时读取配置文件、初始化数据库连接池
何时应该正确使用init函数
不合理的例子:
package utils
import (
"database/sql"
_ "github.com/go-sql-driver/mysql"
)
var DB *sql.DB
// 在init中链接数据库
func init() {
dsn := "foreverool:010101@tcp(127.0.0.1:3306)/study_mysql?charset=utf8mb4&parseTime=True&loc=Local"
db, err := sql.Open("mysql", dsn)
if err != nil {
panic(err)
}
err = db.Ping()
if err != nil {
panic(err)
}
DB = db
}
为什么上述例子不合理呢?
-
由于
init函数的返回错误,所以在内部我们只能通过panic来展示错误,这样做程序就中止了,如果我们想采取重试机制链接数据库,这样通过init函数没有办法做到。 -
如果我们在对于该文件进行测试,在测试之前,
init函数就已经执行,这可能不是我们想要的,因为我们有可能测试的对象就是连接数据库逻辑是否正确。 -
最后一个缺点就是将数据库连接池赋值给一个全局变量,而全局变量存在一些严重的缺陷。
- 包内任何函数都可以修改全局变量
- 单元测试可能变得更加复杂,因为依赖于全局变量的函数将不再能独立地测试了。
在大多数情况下下,我们应该优先将变量封装起来,而不是将其设置为全局变量。基于这些原因我们应该之前的初始化操作应该被作为一个普通函数来处理:
func CreateDB(dsn string) (*sql.DB, error) { db, err := sql.Open("mysql", dsn) if err != nil { return nil, err } err = db.Ping() if err != nil { return nil, err } return db, nil }这样的函数,错误的处理将由调用者来处理,而不是直接panic,并且该函数可以独立的使用测试函数进行测试。
Ad Hoc函数
Ad Hoc函数是指为解决特定的、临时的问题而编写的函数,并不是为了复用性创建的函数。通常只在特定场景下使用。
阅读完本篇文章:
个人觉得:
如果init函数内部可能出现错误处理,那么就不要使用init函数实现该部分内容而是单独定义一个可以被调用者显式调用的函数。
如果init函数实现的功能需要单元测试该部分内容是否正确,那么就不要使用init函数,而是单独定义。
零值的概念
我们创建的每个变量在其初始化时,其值至少被设置位零,也就是当我们声明变量时,go在编译过程中,会自动位该变量进行初始化,也就是为相应的变量的存储空间内存储相应的零值。如果我们在声明变量的时候就指定初始值,那么该变量在使用的时候,其值就是我们预先指定的值。 所谓“零值”就是指每个字节的每一位都被设置为零。
零值确保了数据的完整性,也就是说在我们使用一个声明的变量过程中,该变量符合我们的预期而不是在使用的时候出现一些未知的值存在我们的变量中。
go语言的内置类型的零值如下:
boolean: falseInteger: 0Float: 0.0Complex:0iString: “"(empty)Pointer: nilrune: 0byte: 0
复合类型由一个或多个基本类型组成,其零值遵循【成员各自取对应的类型零值】规则。
-
数组: 数组的每个元素都取该元素类型的零值,与数组长度无关。
-
结构体: 结构体的零值是【结构体每个字段都取该字段类型的零值】,嵌套结构体也遵循此规则,逐层递归赋零值。
-
引用类型:
引用类型的零值都是
nil- 切片
[]int,nil切片的len()、cap()均为0,可直接使用append()无需手动初始化。
// 查看空结构体的值 var nilSlice []int if nilSlice == nil { fmt.Println("nil slice") } else { fmt.Printf("%+v\n", nilSlice) } // output : nil slice //查看nil slice len() cap() fmt.Printf("len=%d, cap=%d\n", len(nilSlice), cap(nilSlice)) // output:len=0, cap=0 // 对nil slice进行append nilSlice = append(nilSlice, 1) fmt.Printf("len=%d, cap=%d\n", len(nilSlice), cap(nilSlice)) fmt.Println(nilSlice) // output: // len=1, cap=1 // [1] var nilSlice1 []int // 使用函数添加元素,但是传入的参数是nil AppendElement(nilSlice1, 1) if nilSlice1 == nil { fmt.Println("nil slice") } else { fmt.Printf("len=%d, cap=%d\n", len(nilSlice), cap(nilSlice)) fmt.Println(nilSlice1) } // output: nil slice // 由于形参是值传递,而通过函数传递给的nilSlice1最终添加了元素并没有返回给main。-
字典map[k]v ,
nilmap无法直接添加键值对,必须通过make进行初始化,或者字面量初始化map[int]int{}。var nilmap map[int]int fmt.Println(len(nilmap)) // output : 0 //直接添加键值对 nilmap[1] = 12 if nilmap == nil { fmt.Println("nil map") } else { fmt.Println("len=", len(nilmap)) fmt.Println(nilmap) } // output: // panic: assignment to entry in nil map [recovered] // panic: assignment to entry in nil map //所以为了程序的健壮性,所以在使用map的时候尽量先对map进行nil判断,然后在进行业务处理 -
通道
chan Tnil通道无法进行发送/接受,必须通过make进行使用。 -
函数
nil的直接调用会引发panic。 -
指针
nil指针无法解引用,如果解引用会引发panic。 -
接口
nil接口的零值要求动态类型和动态值都为nil,nil接口无法调用任何方法。
- 切片
overusing-getters-and-setters
Overusing getters and setters
说起getters 和setters我个人感觉在java中十分常见,由于java是纯面向对象语言,所以经常会将某些字段定义为private然后使用getter 和setter进行操作该priavte字段。但是在Go语言中我在很多源码中并没有看到getter和setter,而是直接操作struct中的字段。除非该字段被设置为当前包可见。
首先说明:
Go不强制使用getter和setter,在标准库中也不强制使用。但是getter和setter具有一些优点:
- 封装了字段的设置与获取行为,允许在获取或者设置过程中添加新的行为(验证字段,返回计算值等)
- 隐藏了内部表示
在Go语言如何使用getter和setter呢?
如果我们要为balance字段设置getter和setter,那么我们的getter方法应该是Balance()而不是GetBalance()。
而setter应该命名为SetBalance。
如果我们的getter和setter就只是简单的取值,赋值,那么没有必要为该字段设置getter和setter。
只有当我们的getter和setter方法有有意义时才使用,遵循go语言的设计哲学
声明与初始化
1 var
关键字var可以用于所有类型的变量设置为初始状态,零值。
type User struct{
Name string
Age uint8
}
var i8 int8
var u8 uint8
var condition bool
var user User
在go语言中字符串底层结构由两个字组成:
type stringStruct struct {
str unsafe.Pointer
len int
}
如果string被设置为nil, 那么字段str则是nil,len为0。
2 短变量声明操作符
短变量声明操作符:=
该操作符包含了声明变量,初始化变量,赋值变量三个步骤。
如果一个变量已经声明了或者定义了,就无法再次使用短变量声明操作符。
转换与类型转换
go语言不支持隐式类型转换,并且显示类型转换不是将原有类型的转换为需要的类型,而是创建一个目标的新变量变量,对其进行赋值,然后将该变量赋值到我们指定的变量中(不是被转换的变量)。
显示转换形式:
// 格式 目标类型(源变量/值)
// string([]byte)
// []byte("string value")
source := "string value"
fmt.Println("source address: ", &source)
target := []byte(source)
fmt.Println("source address: ", &source)
fmt.Println("target address: ", &target)
//output :
// source address: 0xc000026300
// source address: 0xc000026300
// target address: &[115 116 114 105 110 103 32 118 97 108 117 101]
Interface
接口在Go中提供纯粹的抽象。接口的主体只能有方法声明和嵌入式的接口。接口中的方法没有主体,只能在接口中定义方法签名。
1.定义接口的语法
定义接口的语法如下:
type InterfaceName interface{
methodName(argument arguments-type...)returnType
}
可以看到定义接口的语法与定义一个结构体类型相似,都是使用type关键字。
例子:
type Executor interface {
Execute()
}
如果一个接口只有一个方法,那么接口名称则是这个方法的名称+[e]r。在上述例子中,我们的接口只有一个方法Execute所以我们的接口名称为Executor。这种命名规则不是Go硬性条件,而是一种惯例,这种管理方便了解该接口的具体的功能。
在Go语言中,接口可以有一个或多个方法。
type Connection interface {
Open(uri string) (session, error)
Close() error
}
如果一个接口有多个方法,如何命名呢?
根据接口的职责进行命名,一般是名词而非动词。如果一个接口由两个或多个小接口组合而成,那么接口名可以拼接小接口名。
// Implementations must not retain p.
type Reader interface {
Read(p []byte) (n int, err error)
}
type Writer interface {
Write(p []byte) (n int, err error)
}
// ReadWriter is the interface that groups the basic Read and Write methods.
type ReadWriter interface {
Reader
Writer
}
2. 实现接口
在Go语言中接口不像Java中那样需要显示使用implements关键字实现接口,而是采用一种隐式的方式,只要一个类型具有在接口中定义的所有方法,则该类型是实现该接口的。
type Executor interface {
Execute()
}
type Thread struct {
}
func (t Thread) Execute() {
fmt.Println("Executing thread")
}
func TestInterface(t *testing.T) {
var exe Executor
exe = Thread{}
exe.Execute()
}
// output : Executing thread
如果一个类型没有实现接口的中的所有方法,那么在将该对象赋值给接口变量的时候,编译会发生错误。
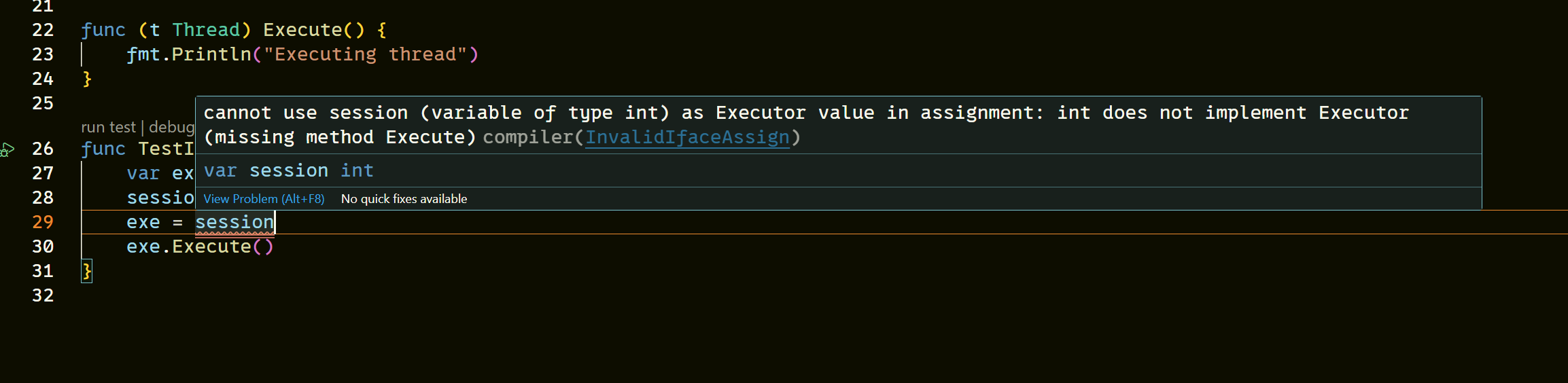
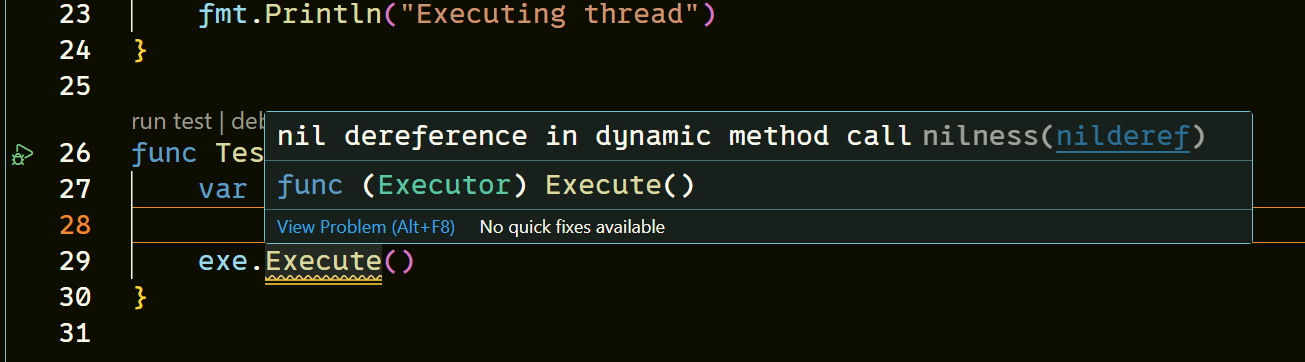
由于接口中的方法没有函数体,所以当我们在没有给接口变量赋值相应的对象时,直接使用接口那么该接口变量将是无用的,此时该变量将被设置为nil,如果调用一个没有赋值过的接口变量,则会触发panic。
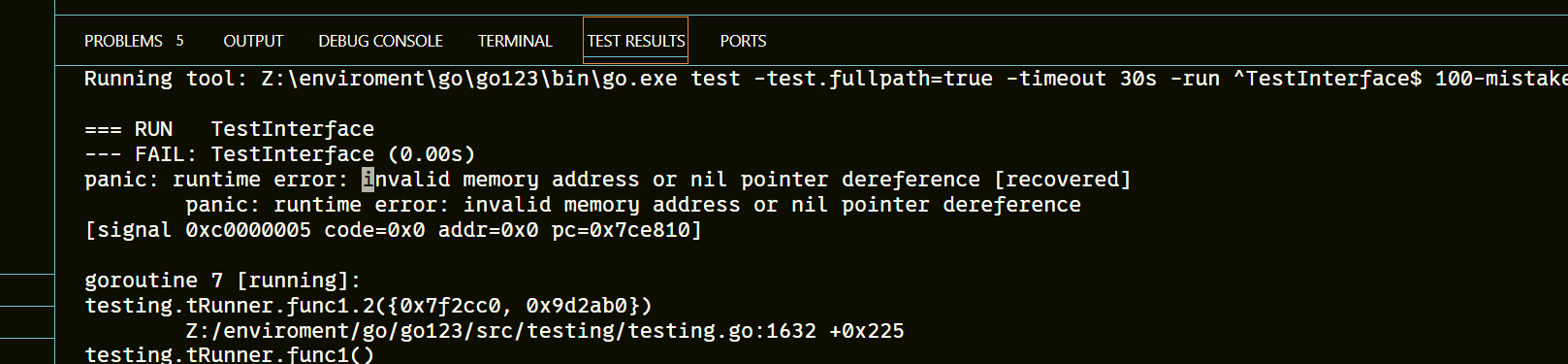
要实现一个接口,必须实现该接口的所有方法,如果仅仅实现了接口的一部分方法,那还是意味着没有实现该接口,也就无法将该对象赋值给接口变量了
type Connection interface {
Open(uri string) (session, error)
Close() error
}
type HttpConnnection struct{}
func (h HttpConnnection) Close() error {
return nil
}
func TestInterface(t *testing.T) {
var connection Connection
connection = HttpConnnection{}
}

3. 为什么要隐式实现
Go语言的设计哲学是简洁、实用、松耦合,隐式实现接口正是这一哲学的集中体现。
- 极致的简洁性:消除了冗余代码,符合“少即是多”
在
Go语言中不需要使用类似implements关键字显示实现接口,那么这样就减少了不必要的代码,如果一个类型所以要实现的接口变了,那么就需要手动的修改类型代码,这样做显得冗余。 - 松耦合:实现者与接口解耦,支持“接口后置” 隐式实现的核心优势:实现者无需感知接口的存在,一个类型可以先定义并实现方法,后续再定义接口来“适配”这个类型,而非必须先定义接口然后再让类型去迎合接口。
- 灵活性:适配已有类型,符合“开闭原则” 隐式实现允许你为已有类型(甚至第三方库类型)适配新接口,而无需修改原有类型的源码。
4. 多态性
如果一个函数的参数是接口类型,然后函数体中使用了该接口中的多个方法,我们无需知道传递的到底是什么对象,只需要知道该方法可以被调用即可,因为他们实现了同一个接口,返回类型、函数参数都是相同的,所以可以在函数参数中传递不同的对象类型(只要实现了相同的接口即可)
type Bird interface {
Fly()
}
type Eagle struct{}
func (e Eagle) Fly() {
fmt.Printf("I'm Eagle.\n I'm flying over the cloud!\n")
}
type Pigeon struct {
}
func (p Pigeon) Fly() {
fmt.Printf("I'm Pigeon.\n I'm flying on normal height\n")
}
type Penguin struct{}
func (p Penguin) Fly() {
fmt.Printf("I'm Penguin.\n I can not fly\n")
}
func flyNow(bird Bird) {
bird.Fly()
}
func TestInterface(t *testing.T) {
flyNow(Eagle{})
flyNow(Pigeon{})
flyNow(Penguin{})
}
我们以游戏视角来看,所有英雄都有3个技能,只是每个技能效果是不同的,但是用户通过键盘输入是一样的,我们可以为每个英雄定义一个类型,然后再与键盘交互的时候传入相应的类型给接口类型即可。
package utils
import (
"bufio"
"fmt"
"os"
"strings"
)
type Hero interface {
Skill1() string
Skill2() string
Skill3() string
HandInput(input string) string
}
// 战士
type Warrior struct {
Name string
}
func (w Warrior) Skill1() string {
return fmt.Sprintf("[%s] 释放技能1:冲锋!造成30物理伤害!", w.Name)
}
func (w Warrior) Skill2() string {
return fmt.Sprintf("[%s] 释放技能2:锁链!造成10物理伤害,并控制敌方0.5s!", w.Name)
}
func (w Warrior) Skill3() string {
return fmt.Sprintf("[%s] 释放技能3:斩杀!造成100物理伤害,100魔法伤害!", w.Name)
}
func (w Warrior) HandInput(input string) string {
input = strings.TrimSpace(input)
input = strings.ToLower(input)
switch input {
case "q":
return w.Skill1()
case "w":
return w.Skill2()
case "e":
return w.Skill3()
default:
return fmt.Sprintf("[%s] 无效输入!请输入q/w/e释放相应技能", w.Name)
}
}
// 法师
type Mage struct {
Name string
}
func (m Mage) Skill1() string {
return fmt.Sprintf("[%s] 释放技能1:火球术!造成20魔法伤害!", m.Name)
}
func (m Mage) Skill2() string {
return fmt.Sprintf("[%s] 释放技能2:冰锥术!造成12魔法伤害,并控制敌方0.5s!", m.Name)
}
func (m Mage) Skill3() string {
return fmt.Sprintf("[%s] 释放技能3:斩杀!造成100物理伤害,100魔法伤害!", m.Name)
}
func (m Mage) HandInput(input string) string {
input = strings.TrimSpace(input)
input = strings.ToLower(input)
switch input {
case "q":
return m.Skill1()
case "w":
return m.Skill2()
case "e":
return m.Skill3()
default:
return fmt.Sprintf("[%s] 无效输入!请输入q/w/e释放相应技能", m.Name)
}
}
func GameInteraction(hero Hero) {
scanner := bufio.NewScanner(os.Stdin)
fmt.Printf("\n欢迎使用英雄【%T】!输入1/2/3释放技能,输入q退出\n", hero)
for {
fmt.Print("请输入指令:")
scanner.Scan()
input := scanner.Text()
if input == "quit" {
fmt.Println("退出游戏交互!")
break
}
result := hero.HandInput(input)
fmt.Println(result)
}
}
分析上述代码我们知道,游戏交互界面主要考虑的是用户输入了什么,不考虑英雄技能是如何施展的,而且每一个英雄都有相同的行为,释放技能,处理输入。所以在游戏交互的时候,我们直接使用接口,哪怕后续技能效果改变了也不影响我们的交互逻辑。
5. empty interface
在Go语言中,没有任何方法的接口称之为空接口。
由于所有类型都满足空接口,所以我们可以将任意类型的值赋给空接口变量。
func TestInterface(t *testing.T) {
var empty interface{} // 也可以定义为any
// 整数
empty = uint(1)
fmt.Printf("empty type is %T\n", empty)
empty = int(1)
fmt.Printf("empty type is %T\n", empty)
// 浮点数
empty = float32(1.12)
fmt.Printf("empty type is %T\n", empty)
empty = float64(1.12)
fmt.Printf("empty type is %T\n", empty)
// boolean
empty = true
fmt.Printf("empty type is %T\n", empty)
// 自定义类型
empty = User{Name: "foreverool"}
fmt.Printf("empty type is %T\n", empty)
// slice
empty = []int{1, 2, 3, 4}
fmt.Printf("empty type is %T\n", empty)
// map
m := make(map[string]int)
m["c"] = 1
m["a"] = 2
empty = m
fmt.Printf("empty type is %T\n", empty)
// pointer
mp := &m
empty = mp
fmt.Printf("empty type is %T\n", empty)
// function
empty = func() {}
fmt.Printf("empty type is %T\n", empty)
}
// output:
// empty type is uint
// empty type is int
// empty type is float32
// empty type is float64
// empty type is bool
// empty type is codeandproject.User
// empty type is []int
// empty type is map[string]int
// empty type is *map[string]int
// empty type is func()
在Go 1.18中引入了any这个空接口的内置别名。也就是说为了书写简单,可以直接使用any,其和interface{}语义、功能都是完全等价的。
然后我们在来看看标准库中是如何使用any的
func Println(a ...any) (n int, err error) {
return Fprintln(os.Stdout, a...)
}
func Printf(format string, a ...any) (n int, err error) {
return Fprintf(os.Stdout, format, a...)
}
我们以Println函数为例,无论我们传递什么类型参数,Println都能打印,就是因为其参数类型是any,在Go语言中所有类型都实现了空接口!!!
6. 方法集
方法集是使类型隐式实现接口的一组方法。
思考: 接口的实现者的方法的接收者是值还是指针?
答案:接口方法不指定实现类型应该具有指针接收器还是值接收器。
对于方法的接收者来说,一般情况下,如果需要对该类型内部的字段进行修改,那么会定义该方法的接收者是指针类型。如果有一个方法的接收者是指针类型,那么我们统一将该类型的所有方法的接收者都为指针类型。
当然在调用方法的时候,Go编译器会自动转换T为*T。
type Form struct {
account string
password string
}
func (f *Form) Account() string {
return f.account
}
func (f *Form) SetAccount(account string) error {
if len(account) > 30 {
return errors.New("超出最大长度")
}
f.account = account
return nil
}
func (f *Form) SetPassword(password string) error {
if len(password) > 30 {
return errors.New("超出最大长度")
}
f.password = password
return nil
}
func ReceiverTest() {
// 值而非指针
form := Form{}
form.SetAccount("foreverool")
form.SetPassword("010101")
fmt.Println(form.Account())
}
- 如果方法接收者是值类型【T】,在调用方法的时候会拷贝整个实例,方法内对字段的修改只作用于拷贝,原实例的字段不会被改变。
- 如果方法接收者是指针类型【*T】, 在调用方法的时候传递的是实例的内存地址,方法内对字段的修改会直接作用于原实例。
但是接口不像普通的方法调用那样,编译器会自动转换,如果一个类型实现了一个接口,并且这个类型的所有方法的接收者是指针类型,那么如果你传递给该接口变量一个值类型,那么会引发编译错误。

这里需要将Form{}的地址赋值给former接口变量。
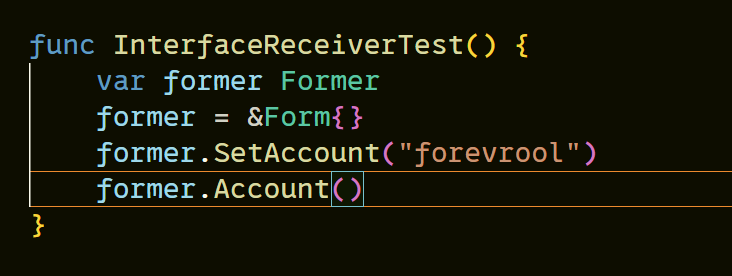
造成该结果的原因是*Form实现了该接口而不是Form实现了。
那么相反的情况会如何呢? Form实现接口,传入该变量的地址会如何?
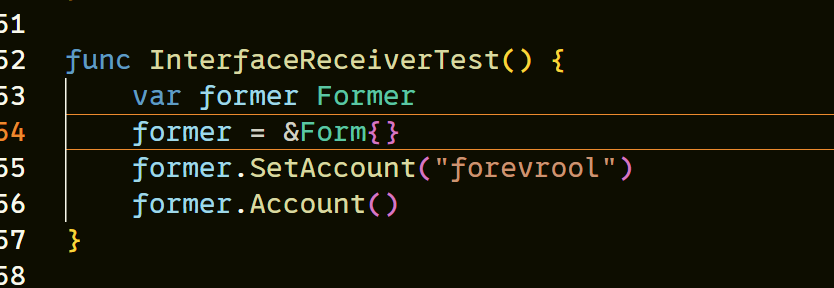
并没有引起任何错误,那就意味着当我们的方法集使用值接收器,那么就意味着T和*T都实现了该接口。
7. 接口与结构体
在Go语言中没有继承的概念,而是通过组合实现与继承一样的效果。我们可以通过将接口嵌入到结构体中(依赖注入),在使用该接口时,需要将实现了该接口的对象实例赋值到结构体字段中,这样该结构体可以直接调用该接口(Go语言的语法糖)。
需要注意的是,虽然结构体可以直接调用接口的方法,但不意味着该结构体实现了该接口,只是隐式的调用该结构体的某个字段的方法而已
- 接口嵌入的本质是匿名字段
type Mover interface {
Move()
}
type Jumper interface {
Jump()
}
type Person struct {
Name string
Mover
Jumper
}
type NormalPerson struct{}
func (n NormalPerson) Move() {
fmt.Println("我正以每小时5公里的速度前进")
}
func (n NormalPerson) Jump() {
fmt.Println("我每次跳跃30cm")
}
type AthlecticPerson struct{}
func (a AthlecticPerson) Move() {
fmt.Println("我正以每小时10公里的速度前进")
}
func (a AthlecticPerson) Jump() {
fmt.Println("我每次跳跃60cm")
}
func TestEmbededInterface(t *testing.T) {
normal := NormalPerson{}
athletic := AthlecticPerson{}
person := Person{
Name: "Normal Person",
Mover: normal,
Jumper: athletic,
}
person.Move()
person.Jump()
}
上述代码中Person结构体嵌套了Mover和Jumper接口,在使用person之前先将实现Mover和Jumper接口的类型的实例赋值到了person相应的匿名字段中,而在最后调用的时候直接调用只是Go的语法糖,其实际代码为:
person.Mover.Move()
person.Jumper.Jump()
- 如果直接使用一个未被赋值一个实现相应接口的类型实例,直接使用该变量,则会直接引发
panic。 - 如果结构体中也定义了与字段接口同名的方法,会覆盖掉字段中的方法。
func (p Person) Move() {
fmt.Println("我覆盖了!")
}
// 执行上面的代码
// output:
// 我覆盖了!
// 我每次跳跃60cm